Talking Face Generation (TFG) reconstructs facial motions concerning lips given speech input, which aims
to generate high-quality, synchronized, and lip-readable videos. Previous efforts have achieved success in
generating quality and synchronization, and recently, there has been an increasing focus on the importance
of intelligibility. Despite these efforts, there remains a challenge in achieving a balance among quality,
synchronization, and intelligibility, often resulting in trade-offs that compromise one aspect in favor of
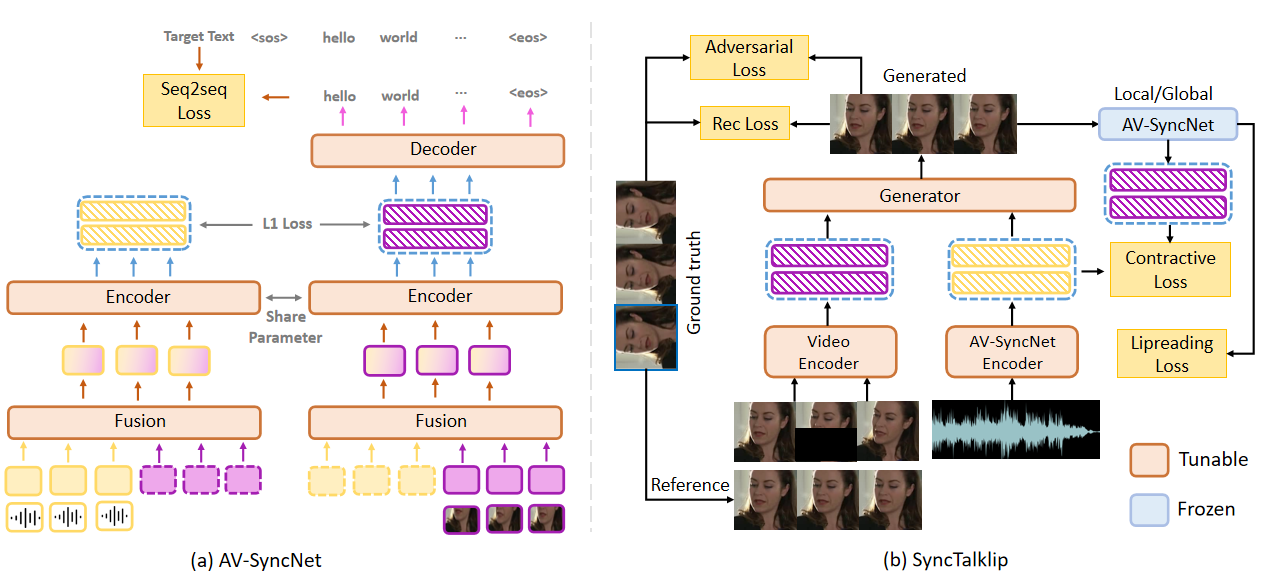
another. In light of this, we propose SyncTalklip, a novel dual-tower framework designed to overcome the
challenges of synchronization while improving lip-reading performance. To enhance the performance of
SyncTalklip in both synchronization and intelligibility, we design AV-SyncNet, a pretrained multi-task
model, aiming to achieve a dual-focus on synchronization and intelligibility. Moreover, we propose a novel
cross-modal contrastive learning bringing audio and video closer to enhance synchronization. Experimental
results demonstrate that SyncTalklip achieves State-of-the-art performance in quality, intelligibility,
and synchronization. Furthermore, extensive experiments have demonstrated our model's generalizability
across domains.
Note: The code will be released after published.